About the Challenge
Tabular data in the form of CSV files is the common input format in a data analytics pipeline. However, a lack of understanding of the semantic structure and meaning of the content may hinder the data analytics process. Thus gaining this semantic understanding will be very valuable for data integration, data cleaning, data mining, machine learning and knowledge discovery tasks. For example, understanding what the data is can help assess what sorts of transformation are appropriate on the data.
Tables on the Web may also be the source of highly valuable data. The addition of semantic information to Web tables may enhance a wide range of applications, such as web search, question answering, and knowledge base (KB) construction.
Tabular data to Knowledge Graph (KG) matching is the process of assigning semantic tags from Knowledge Graphs (e.g., Wikidata or DBpedia) to the elements of the table. This task however is often difficult in practice due to metadata (e.g., table and column names) being missing, incomplete or ambiguous.
The SemTab challenge aims at benchmarking systems dealing with the tabular data to KG matching problem, so as to facilitate their comparison on the same basis and the reproducibility of the results.
The 2023 edition of this challenge will be collocated with the 22st International Semantic Web Conference and the 18th International Workshop on Ontology Matching.
Proceedings
SemTab 2023 proceedings have been published as volume 3557 of CEUR-WS.
-
Results of SemTab 2023
Oktie Hassanzadeh, Nora Abdelmageed, Vasilis Efthymiou, Jiaoyan Chen, Vincenzo Cutrona, Madelon Hulsebos, Ernesto Jiménez-Ruiz, Aamod Khatiwada, Keti Korini, Benno Kruit, Juan Sequeda, Kavitha Srinivas. -
Semantic Annotation of
TSOTSATable Dataset (short paper)
Azanzi Jiomekong, Uriel Melie, Hippolyte Tapamo, Gaoussou Camara -
TorchicTab: Semantic Table Annotation with Wikidata and Language Models
Ioannis Dasoulas, Duo Yang, Xuemin Duan, Anastasia Dimou -
SemTex: A Hybrid Approach for Semantic Table Interpretation
Emil G. Henriksen, Alan M. Khorsid, Esben Nielsen, Adam M. Stück, Andreas S. Sørensen, Olivier Pelgrin -
DREIFLUSS: A Minimalist Approach for Table Matching
Vishvapalsinhji Parmar, Alsayed Algergawy -
Semantic Annotation of Tabular Data for Machine-to-Machine Interoperability via
Neuro-Symbolic Anchoring
Shervin Mehryar, Remzi Celebi -
Exploring Naive Bayes Classifiers for Tabular Data to Knowledge Graph Matching
Brice Foko, Azanzi Jiomekong, Hippolyte Tapamo, Jérémy Buisson, Sanju Tiwari -
Kepler-aSI at SemTab 2023 (short paper)
Wiem Baazouzi, Marouen Kachroudi, Sami Faiz
Participation: Forum and Registration
We have a discussion group for the challenge where we share the latest news with the participants and we discuss issues risen during the evaluation rounds.
Note that participants can join SemTab at any Round for any of the tasks/tracks.
Challenge Tracks
Accuracy Track
The evaluation of systems regarding accuracy is similar to prior versions of the SemTab.That is, to illustrate the accuracy of the submissions, we evaluate systems on typical multi-class classification metrics as detailed below.
In addition, we adopt the "cscore" for the CTA task to reflect the distance in the type hierarchy between the predicted column type and the ground truth semantic type.
Matching Tasks:
- CTA Task: Assigning a semantic type (a DBpedia class as fine-grained as possible) to a column.
- CEA Task: Matching a cell to a Wikidata entity.
- CPA Task: Assigning a KG property to the relationship between two columns.
- NEW! Table Topic Detection: Assigning a KG class to a table.
- NEW! Column-Qualifier Annotation: Predicting both main properties and qualifiers for n-ary relations that are expressed by three table columns.
- Average Precision
- Average Recall
- Average F1
- Cscore
- Accuracy
Datasets Track
This year, we welcome two different kind of Dataset contributions. Please find the details below.New dataset contributions:
The data that table-to-Knowledge-Graph matching systems are trained and evaluated on, is critical for their accuracy and relevance.We invite dataset submissions that provide challenging and accessible new datasets to advance the state-of-the-art of table-to-KG matching systems.
Preferably, these datasets provide tables along with their ground truth annotations for at least one of CEA, CTA and CPA tasks.
The dataset may be general or specific to a certain domain.
Submissions will be evaluated according to provide the following:
- Description of the data collection, curation, and annotation processes.
- Availability of documentation with insights in the dataset content.
- Publicly accessible link to the dataset (e.g. Zenodo) and its DOI.
- Explanation of maintenance and long-term availability.
- Clear description of the envisioned use-cases.
- Application in which the dataset is used to solve an exemplar task.
NEW! dataset revision contributions:
Besides entirely new datasets, we also encourage revisions of existing datasets and their annotations. Revisions can be of any kind as below, but we welcome alternative revisions:- Revisited annotations with improved quality.
- Revisited data with improved quality.
- New annotations for an existing dataset enabling new tasks on it.
Submission format Datasets Track:
We ask participants to describe their datasets through easychair in a short paper (max 6 pages) that discusses how the respective criteria are covered, while also including a link to the resources. The link to the resources may be private, until the submission is evaluated by the SemTab organisers. See paper guidelines below, for more details. More guidance for creating, documenting and publishing datasets can be found here.Artifacts Availability Badge
New this year is the Artifacts Availability Badge which is applicable to the Accuracy Track as well as the Datasets Track.The goal of this badge is to motivate authors to publish and document their systems, code, and data, so that others can use these artifacts and potentially reproduce or build on the results.
This badge is given if all resources are verified to satisfy the below criteria.
The criteria used to assess submissions (both accuracy and dataset submissions) are:
- Publicly accessible data (if applicable).
- Publicly accessible source code.
- Clear documentation of the code and data.
- Open-source dependencies.
Important dates
All dates 2023, deadlines 11:59pm AoE:- April 14: Release of Round 1 datasets.
- April 14 -
May 15May 17: Round 1. - May 18 - June 22: Round 2.
July 5July 13: System results announced.-
July 14July 19: Paper submissions (Systems and Datasets). -
July 21July 26: Invitations to present at the ISWC 2023 conference. August 6August 8: Notifications of acceptance.- September 15: Submission of Final papers.
- November 6 - 10: Challenge presentation during OM workshop.
- November 6 - 10: Challenge Presentation during ISWC.
Datasets and tasks per round
Round #1
Cell Entity Annotation by Wikidata (WikidataTablesR1-CEA)
This is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge
Graph
Matching".
It is to annotate column cells (entity mentions) in a table with entities of
Wikidata.
Note: The evaluation will be based on annotations using Feb 1, 2023 version of
Wikidata. Participants may use this
static dump from Feb 1, 2023, or the public Wikidata endpoint (or its API).
Task Description
The task is to annotate each target cell with an entity of Wikidata. Each submission should contain the annotation of the target cell. One cell can be annotated by one entity with the prefix of http://www.wikidata.org/entity/. Any of the equivalent entities of the ground truth entity are regarded as correct. Case is NOT sensitive.
The submission file should be in CSV format. Each line should contain the annotation of one cell which is identified by a table id, a column id and a row id. Namely one line should have four fields: "Table ID", "Row ID", "Column ID" and "Entity IRI". Each cell should be annotated by at most one entity. The headers should be excluded from the submission file. Here is an example: "OHGI1JNY","32","1","http://www.wikidata.org/entity/Q5484". Please use the prefix of http://www.wikidata.org/entity/ instead of https://www.wikidata.org/wiki/ which is the prefix of the Wikidata page URL.
Notes:- Table ID does not include filename extension; make sure you remove the .csv extension from the filename.
- Column ID is the position of the column in the table file, starting from 0, i.e., first column's ID is 0.
- Row ID is the position of the row in the table file, starting from 0, i.e., first row's ID is 0.
- One submission file should have NO duplicate lines for one cell.
- Annotations for cells out of the target cells are ignored.
Dataset
- Link
- Round #1 WikidataTables Dataset
- Description
-
The dataset contains:
- evaluator codes (CEA_WD_Evaluator.py)
- the validation set (DataSets/Valid/gt/cea_gt.csv, DataSets/Valid/tables)
- the testing set (DataSets/Test/tables, DataSets/Test/target/cea_target.csv)
- Format
- One table is stored in one CSV file. Each line corresponds to a table row. The first row may either be the table header or content. The target cells for annotation are saved in a CSV file.
Evaluation Criteria
Precision, Recall and F1 Score are calculated: \[Precision = {{correct\_annotations \#} \over {submitted\_annotations \#}}\] \[Recall = {{correct\_annotations \#} \over {ground\_truth\_annotations \#}}\] \[F1 = {2 \times Precision \times Recall \over Precision + Recall}\]
Notes:- # denotes the number.
- \(F1\) is used as the primary score, and \(Precision\) is used as the secondary score.
- One target cell, one ground truth annotation, i.e., # ground truth annotations = # target cells. The ground truth annotation has already covered all equivalent entities (e.g., wiki page redirected entities); the ground truth is hit if one of its equivalent entities is hit.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_WikidataTablesR1_CEA.csv.Column Type Annotation by Wikidata (CTA-WD)
This is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge
Graph
Matching".
It's to annotate an entity column (i.e., a column composed of entity mentions) in a
table with
types from Wikidata.
Note: The evaluation will be based on annotations using Feb 1, 2023 version of
Wikidata. Participants may use this
static dump from Feb 1, 2023, or the public Wikidata endpoint (or its API).
Task Description
The task is to annotate each entity column by items of Wikidata as its type. Each column can be annotated by multiple types: the one that is as fine grained as possible and correct to all the column cells, is regarded as a perfect annotation; the one that is the ancestor of the perfect annotation is regarded as an okay annotation; others are regarded as wrong annotations.
The annotation can be a normal entity of Wikidata, with the prefix of http://www.wikidata.org/entity/, such as http://www.wikidata.org/entity/Q8425. Each column should be annotated by at most one item. A perfect annotation is encouraged with a full score, while an okay annotation can still get a part of the score. Example: "KIN0LD6C","0","http://www.wikidata.org/entity/Q8425". Please use the prefix of http://www.wikidata.org/entity/ instead of the URL prefix https://www.wikidata.org/wiki/.
The annotation should be represented by its full IRI, where the case is NOT sensitive. Each submission should be a CSV file. Each line should include a column identified by table id and column id, and the column's annotation (a Wikidata item). It means one line should include three fields: "Table ID", "Column ID" and "Annotation IRI". The headers should be excluded from the submission file.
Notes:- Table ID is the filename of the table data, but does NOT include the extension.
- Column ID is the position of the column in the input, starting from 0, i.e., first column's ID is 0.
- One submission file should have NO duplicate lines for each target column.
- Annotations for columns out of the target columns are ignored.
Dataset
- Link
- Round #1 WikidataTables Dataset
- Description
-
The dataset contains:
- evaluator codes (CTA_WD_Evaluator.py)
- the validation set (DataSets/Valid/gt/cta_gt.csv, DataSets/Valid/gt/cta_gt_ancestor.json, DataSets/Valid/gt/cta_gt_descendent.json, DataSets/Valid/tables)
- the testing set (DataSets/Test/tables, DataSets/Test/target/cta_gt.csv)
- Format
- One table is stored in one CSV file. Each line corresponds to a table row. The first row may either be the table header or content. The target columns for annotation are saved in a CSV file. The CTA GTs' ancestors and descendents are saved in two json files, respectively.
Evaluation Criteria
We encourage one perfect annotation, and at same time score one of its ancestors (okay annotation). Thus we calculate Approximate Precision (\(APrecision\)), Approximate Recall (\(ARecall\)), and Approximate F1 Score (\(AF1\)): \[APrecision = {\sum_{a \in all\ annotations}g(a) \over all\ annotations\ \#}\] \[ARecall = {\sum_{col \in all\ target\ columns}(max\_annotation\_score(col)) \over all\ target\ columns\ \#}\] \[AF1 = {2 \times APrecision \times ARecall \over APrecision + ARecall}\]
Notes:- # denotes the number.
-
\(
g(a) =
\begin{cases}
1.0, & \text{ if } a \text{ is a perfect annotation} \\
0.8^{d(a)}, & \text{ if } a \text{ is an ancestor of the perfect annotation and
} d(a) < 5 \\ 0.7^{d(a)}, & \text{ if } a \text{ is a descendent of the perfect
annotation and } d(a) < 3 \\ 0, & otherwise \end{cases} \)
where \(d(a)\) is the depth to the perfect annotation. E.g., \(d(a)=1\) if \(a\) is a parent of the perfect annotation, and \(d(a)=2\) if \(a\) is a grandparent of the perfect annotation.
- \( max\_annotation\_score(col) = \begin{cases} g(a), & \text{ if } col \text{ has an annotation } a \\ 0, & \text{ if } col \text{ has no annotation } \end{cases} \)
- \(AF1\) is used as the primary score, and \(APrecision\) is used as the secondary score.
- A cell may have multiple equivalent Wikidata items as its GT (e.g., redirected pages Q20514736 and Q852446). For an annotated entity, our evaluator will calculate the score with each GT entity and select the maximum score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_WikidataTablesR1_CTA.csv.Column Property Annotation by Wikidata (CPA-WD)
This is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge
Graph
Matching".
It is to annotate column relationships in a table with properties of
Wikidata.
Note: The evaluation will be based on annotations using Feb 1, 2023 version of
Wikidata. Participants may use this
static dump from Feb 1, 2023, or the public Wikidata endpoint (or its API).
Task Description
The task is to annotate each column pair with a property of Wikidata. Each submission should contain an annotation of a target column pair. Note the order of the two columns matters. The annotation property should start with the prefix of http://www.wikidata.org/prop/direct/. Case is NOT sensitive.
The submission file should be in CSV format. Each line should contain the annotation of two columns which is identified by a table id, column id one and column id two. Namely one line should have four fields: "Table ID", "Column ID 1", "Column ID 2" and "Property IRI". Each column pair should be annotated by at most one property. The headers should be excluded from the submission file. Here is an example: "OHGI1JNY","0","1","http://www.wikidata.org/prop/direct/P702". Please use the prefix of http://www.wikidata.org/prop/direct/ instead of https://www.wikidata.org/wiki/ which is the prefix of the Wikidata page URL.
Notes:- Table ID does not include filename extension; make sure you remove the .csv extension from the filename.
- Column ID is the position of the column in the table file, starting from 0, i.e., first column's ID is 0.
- One submission file should have NO duplicate lines for one column pair.
- Annotations for column pairs out of the targets are ignored.
Dataset
- Link
- Round #1 WikidataTables Dataset
- Description
-
The dataset contains:
- evaluator codes (CPA_WD_Evaluator.py))
- the validation set (DataSets/Valid/gt/cpa_gt.csv, DataSets/Valid/tables)
- the testing set (DataSets/Test/tables, DataSets/Test/target/cpa_target.csv)
- Format
- One table is stored in one CSV file. Each line corresponds to a table row. The first row may either be the table header or content. The target cells for annotation are saved in a CSV file.
Evaluation Criteria
Precision, Recall and F1 Score are calculated: \[Precision = {{correct\_annotations \#} \over {submitted\_annotations \#}}\] \[Recall = {{correct\_annotations \#} \over {ground\_truth\_annotations \#}}\] \[F1 = {2 \times Precision \times Recall \over Precision + Recall}\]
Notes:- # denotes the number.
- \(F1\) is used as the primary score, and \(Precision\) is used as the secondary score.
- One target column pair, one ground truth annotation, i.e., # ground truth annotations = # target column pairs.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_WikidataTablesR1_CPA.csv.tFood Topic Detection (tFood-TD)
This is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". It's to annotate an entire table to instances/entities or types/classes from Wikidata (for offline use: 2023-03-20 or 2023-02-01).
Task Description
The task is to annotate each table to a KG entity or class.
Each submission should be a CSV file. Each line should include a table id and table's annotation (a Wikidata entity/class).
Dataset
- Links
- (1) tFood dataset at SemTab 2023 Round 1
- Description
- (2) Evaluator Codes for tFood at SemTab 2023 Round 1
-
The dataset provide:
- Table Types Two types of tables to be annotated in tFood dataset: 1) Horizontal Relational Tables and 2) Entity Tables.
- Annotation tasks per table type:
- a) Horizontal Relational Tables
1) Topic Detection (TD)
2) Cell Entity Annotation (CEA)
3) Column Type Annotation (CTA)
4) Column Property Annotation (CPA) - b) Entity Tables
1) Topic Detection (TD)
2) Cell Entity Annotation (CEA)
- Validation/Test splits: the ground truth data for each task is provided in the validation (val) set however, it is not the case with the test set.
- Irrelevant Ground Truth:
Please ignore any other provided ground truth and targets other than the tasks specified in this page for for each table type.
E.g., exclude:entity/val/gt/cpa_gt.csvandentity/val/targets/cpa_gt.csv - Evaluator Code could be used to evaluate your solutions using the provided ground truth data for the validation (val) set.
- Evaluation Rules
1) One submission file should have NO duplicate lines for each target column.
2) Table ID is the filename of the table data, but does NOT include the extension (i.e. "csv").
3) The annotation should be represented by its full IRI, where the case is NOT sensitive.
4) The headers should be excluded from the submission file. - Submission File Format
General speaking, the submission file should match the format of the provided ground truth file, one file where each line has:
TABLE_ID,ANNOTATION
Evaluation Criteria
Precision, Recall and F1 Score are calculated: \[Precision = {{correct\_annotations \#} \over {submitted\_annotations \#}}\] \[Recall = {{correct\_annotations \#} \over {ground\_truth\_annotations \#}}\] \[F1 = {2 \times Precision \times Recall \over Precision + Recall}\]
Notes:- # denotes the number.
- \(F1\) is used as the primary score, and \(Precision\) is used as the secondary score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_DATASET_TASK.csv.tFood Cell Entity Annotation (tFood-CEA)
This is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". It's to annotate a table cell with entities from Wikidata (for offline use: 2023-03-20 or 2023-02-01).
Task Description
The task is to annotate each table cell to a KG entity.
Each submission should be a CSV file. Each line should include a cell (col_id, row_id) identified by table id and cell's annotation (a Wikidata entity).
Dataset
- Links
- (1) tFood dataset at SemTab 2023 Round 1
- Description
- (2) Evaluator Codes for tFood at SemTab 2023 Round 1
-
The dataset provide:
- Table Types Two types of tables to be annotated in tFood dataset: 1) Horizontal Relational Tables and 2) Entity Tables.
- Annotation tasks per table type:
- a) Horizontal Relational Tables
1) Topic Detection (TD)
2) Cell Entity Annotation (CEA)
3) Column Type Annotation (CTA)
4) Column Property Annotation (CPA) - b) Entity Tables
1) Topic Detection (TD)
2) Cell Entity Annotation (CEA)
- Validation/Test splits: the ground truth data for each task is provided in the validation (val) set however, it is not the case with the test set.
- Irrelevant Ground Truth:
Please ignore any other provided ground truth and targets other than the tasks specified in this page for for each table type.
E.g., exclude:entity/val/gt/cpa_gt.csvandentity/val/targets/cpa_gt.csv - Evaluator Code could be used to evaluate your solutions using the provided ground truth data for the validation (val) set.
- Evaluation Rules
1) One submission file should have NO duplicate lines for each target column.
2) Table ID is the filename of the table data, but does NOT include the extension (i.e. "csv").
3) The annotation should be represented by its full IRI, where the case is NOT sensitive.
4) The headers should be excluded from the submission file.
2) Annotations for cells out of the target cells are ignored. - Submission File Format
General speaking, the submission file should match the format of the provided ground truth file, one file where each line has:
TABLE_ID,COL_ID,ROW_ID,ANNOTATIONfor Horizontal Tables: row_id = 0 means the first row after table header.
for Entity Tables: row_id = 0 means the first row in the file (Entity tables has no horizontal headers to exclude).
Evaluation Criteria
Precision, Recall and F1 Score are calculated: \[Precision = {{correct\_annotations \#} \over {submitted\_annotations \#}}\] \[Recall = {{correct\_annotations \#} \over {ground\_truth\_annotations \#}}\] \[F1 = {2 \times Precision \times Recall \over Precision + Recall}\]
Notes:- # denotes the number.
- \(F1\) is used as the primary score, and \(Precision\) is used as the secondary score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_DATASET_TASK.csv.tFood Column Type Annotation (tFood-CTA)
This is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". It's to annotate a table column with types from Wikidata (for offline use: 2023-03-20 or 2023-02-01).
Task Description
The task is to annotate each table column to a KG concept.
Each submission should be a CSV file. Each line should include a column (col_id) identified by table id and column's annotation (a Wikidata concept).
Dataset
- Links
- (1) tFood dataset at SemTab 2023 Round 1
- Description
- (2) Evaluator Codes for tFood at SemTab 2023 Round 1
-
The dataset provide:
- Table Types Two types of tables to be annotated in tFood dataset: 1) Horizontal Relational Tables and 2) Entity Tables.
- Annotation tasks per table type:
- a) Horizontal Relational Tables
1) Topic Detection (TD)
2) Cell Entity Annotation (CEA)
3) Column Type Annotation (CTA)
4) Column Property Annotation (CPA) - b) Entity Tables
1) Topic Detection (TD)
2) Cell Entity Annotation (CEA)
- Validation/Test splits: the ground truth data for each task is provided in the validation (val) set however, it is not the case with the test set.
- Irrelevant Ground Truth:
Please ignore any other provided ground truth and targets other than the tasks specified in this page for for each table type.
E.g., exclude:entity/val/gt/cpa_gt.csvandentity/val/targets/cpa_gt.csv - Evaluator Code could be used to evaluate your solutions using the provided ground truth data for the validation (val) set.
- Evaluation Rules
1) One submission file should have NO duplicate lines for each target column.
2) Table ID is the filename of the table data, but does NOT include the extension (i.e. "csv").
3) The annotation should be represented by its full IRI, where the case is NOT sensitive.
4) The headers should be excluded from the submission file.
2) Annotations for columns out of the target columns are ignored. - Submission File Format
General speaking, the submission file should match the format of the provided ground truth file, one file where each line has:
TABLE_ID,COL_ID,ANNOTATION
Evaluation Criteria
Precision, Recall and F1 Score are calculated: \[Precision = {{correct\_annotations \#} \over {submitted\_annotations \#}}\] \[Recall = {{correct\_annotations \#} \over {ground\_truth\_annotations \#}}\] \[F1 = {2 \times Precision \times Recall \over Precision + Recall}\]
Notes:- # denotes the number.
- \(F1\) is used as the primary score, and \(Precision\) is used as the secondary score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_DATASET_TASK.csv.tFood Column Property Annotation (tFood-CPA)
This is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". It's to annotate a table column pair with properties from Wikidata (for offline use: 2023-03-20 or 2023-02-01).
Task Description
The task is to annotate column pairs to a KG concept.
Each submission should be a CSV file. Each line should include a column pair (subj_id, obj_id) identified by table id and column pair's annotation (a Wikidata property).
Dataset
- Links
- (1) tFood dataset at SemTab 2023 Round 1
- Description
- (2) Evaluator Codes for tFood at SemTab 2023 Round 1
-
The dataset provide:
- Table Types Two types of tables to be annotated in tFood dataset: 1) Horizontal Relational Tables and 2) Entity Tables.
- Annotation tasks per table type:
- a) Horizontal Relational Tables
1) Topic Detection (TD)
2) Cell Entity Annotation (CEA)
3) Column Type Annotation (CTA)
4) Column Property Annotation (CPA) - b) Entity Tables
1) Topic Detection (TD)
2) Cell Entity Annotation (CEA)
- Validation/Test splits: the ground truth data for each task is provided in the validation (val) set however, it is not the case with the test set.
- Irrelevant Ground Truth:
Please ignore any other provided ground truth and targets other than the tasks specified in this page for for each table type.
E.g., exclude:entity/val/gt/cpa_gt.csvandentity/val/targets/cpa_gt.csv - Evaluator Code could be used to evaluate your solutions using the provided ground truth data for the validation (val) set.
- Evaluation Rules
1) One submission file should have NO duplicate lines for each target column.
2) Table ID is the filename of the table data, but does NOT include the extension (i.e. "csv").
3) The annotation should be represented by its full IRI, where the case is NOT sensitive.
4) The headers should be excluded from the submission file.
2) Annotations for column-pairs out of the target column-pairs are ignored. - Submission File Format
General speaking, the submission file should match the format of the provided ground truth file, one file where each line has:
TABLE_ID,SUBJ_COL_ID,OBJ_COL_ID,ANNOTATION
Evaluation Criteria
Precision, Recall and F1 Score are calculated: \[Precision = {{correct\_annotations \#} \over {submitted\_annotations \#}}\] \[Recall = {{correct\_annotations \#} \over {ground\_truth\_annotations \#}}\] \[F1 = {2 \times Precision \times Recall \over Precision + Recall}\]
Notes:- # denotes the number.
- \(F1\) is used as the primary score, and \(Precision\) is used as the secondary score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_DATASET_TASK.csv.Column Type Annotation using Schema.org terms (R1-SOTAB-CTA-SCH)
R1-SOTAB-CTA-SCH is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". It is based on the WDC-SOTAB benchmark. The goal is to annotate table columns with pre-defined terms from the Schema.org vocabulary.
Task Description
In this task, the goal is to annotate the semantic types of table columns using terms from a pre-defined set of Schema.org terms. The problem is formulated as a multi-class classification problem where each column can be annotated with only one type. The set of pre-defined Schema.org terms consists of 40 terms which are listed in the "cta_labels_round1.txt" file. Examples include telephone, Duration or Place/name.
Each submission should be a CSV file. A line should represent one column prediction. The first column should specify the name of the table, the second column should specify the index of the column in the table and the third column should specify the predicted label. The columns should be named: "table_name", "column_index", "label".
Explanations:
- "table_name" column should include the full name of the table including the extension. (example: Product_corememoriesco.com_September2020_CTA.json.gz)
- "column_index" refers to the position of the column in the table. Column indices in a table start from 0.
- "label" refers to the predicted label. One column should have only one predicted label.
Dataset
- Links
- (1) R1-SOTAB-CTA-SCH Tables at SemTab 2023 Round 1
- Description
- (2) Training annotations, validation annotations, test targets, evaluation script and label space for R1-SOTAB-CTA-SCH.
-
The datasets zip file includes:
- The training set is found in the file "sotab_cta_train_round1.csv" and provides the table names, column indices, and ground truth labels for each column.
- The validation set is found in the file
"sotab_cta_validation_round1.csv" and has the same structure as the
training set. You can use the code "SOTAB_Evaluator.py" to evaluate the
predictions on the validation set. You can run the evaluation by
running:
python SOTAB_Evaluator.py /path/to/submission/file /path/to/ground/truth/file - The test targets can be found in the file "sotab_cta_test_targets_round1.csv". The first column indicates the table name and the second the target column index which needs to be predicted. Submissions need to have one prediction for each target column.
- All tables can be found in the links provided. One table is stored in
one JSON file. Each line corresponds to a table row. The tables do not
have any column headers. You can open a table using the following code:
table_df = pd.read_json(path, compression='gzip', lines=True) - The label set to use for prediction is stored in the "cta_labels_round1.txt" file.
Evaluation Criteria
Calculating Precision, Recall, Macro-F1 Score and Micro-F1 Score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_DATASET_TASK.csv.Columns Property Annotation using Schema.org terms (R1-SOTAB-CPA-SCH)
R1-SOTAB-CPA-SCH is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". It is based on the WDC-SOTAB benchmark. The goal is to annotate the relationship between the main column of a table and other columns with some pre-defined terms from the Schema.org vocabulary.
Task Description
In this task, the goal is to annotate the relationship between the main column of a table and other columns using terms from a pre-defined set of Schema.org terms. The problem is formulated as a multi-class classification problem where each column pair can be annotated with only one label. The set of pre-defined Schema.org terms consists of 50 terms which are listed in the "cpa_labels_round1.txt" file. Examples include telephone, isbn or description.
Each submission should be a CSV file. A line should represent one relationship prediction. The first column should specify the name of the table, the second column should specify the index of the main column, the third should specify the index of the other column and the fourth column should specify the predicted label. The columns should be named: "table_name", "main_column_index", "column_index", "label".
Explanations:
- "table_name" column should include the full name of the table including the extension. (example: Product_corememoriesco.com_September2020_CPA.json.gz)
- "main_column_index" refers to the position of the main column in the table. Main column indices in the WDC-SOTAB benchmark are always at the 0 index.
- "column_index" refers to the position of the column in the table. Non-main-column indices in a table start from 1.
- "label" refers to the predicted label. One column pair should have only one predicted label.
Dataset
- Links
- (1) R1-SOTAB-CPA-SCH Tables at SemTab 2023 Round 1
- Description
- (2) Training annotations, validation annotations, test targets, evaluation script and label space for R1-SOTAB-CPA-SCH.
-
The datasets zip file includes:
- The training set is found in the file "sotab_cpa_train_round1.csv" and provides the table names, main column indices, column indices, and ground truth labels for each column pair.
- The validation set is found in the file
"sotab_cpa_validation_round1.csv" and has the same structure as the
training set. You can use the code "SOTAB_Evaluator.py" to evaluate the
predictions on the validation set. You can run the evaluation by
running:
python SOTAB_Evaluator.py /path/to/submission/file /path/to/ground/truth/file - The test targets can be found in the file "sotab_cpa_test_targets_round1.csv". The first column indicates the table name, the second column indicates the index of the main column in the table, the third column indicates the target column index and the relationship between these two columns needs to be predicted. Submissions need to have one prediction for each target column.
- All tables can be found in the links provided. One table is stored in
one JSON file. Each line corresponds to a table row. The tables do not
have any column headers. You can open a table using the following code:
table_df = pd.read_json(path, compression='gzip', lines=True) - The label set to use for prediction is stored in the "cpa_labels_round1.txt" file.
Evaluation Criteria
Calculating Precision, Recall, Macro-F1 Score and Micro-F1 Score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_DATASET_TASK.csv.Round #2
Column Type Annotation using Schema.org terms (R2-SOTAB-CTA-SCH)
R2-SOTAB-CTA-SCH is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". It is based on the WDC-SOTAB benchmark. The goal is to annotate table columns with pre-defined terms from the Schema.org vocabulary.
Task Description
In this task, the goal is to annotate the semantic types of table columns using terms from a pre-defined set of Schema.org terms. The problem is formulated as a multi-class classification problem where each column can be annotated with only one type. The set of pre-defined Schema.org terms consists of 80 terms which are listed in the "cta_labels_round2.txt" file. Examples include telephone, Duration or Place/name.
Each submission should be a CSV file. A line should represent one column prediction. The first column should specify the name of the table, the second column should specify the index of the column in the table and the third column should specify the predicted label. The columns should be named: "table_name", "column_index", "label".
Explanations:
- "table_name" column should include the full name of the table including the extension. (example: Product_corememoriesco.com_September2020_CTA.json.gz)
- "column_index" refers to the position of the column in the table. Column indices in a table start from 0.
- "label" refers to the predicted label. One column should have only one predicted label.
Dataset
- Links
- (1) R2-SOTAB-CTA Tables at SemTab 2023 Round 2
- Description
- (2) Training annotations, validation annotations, test targets, evaluation script and label space for R2-SOTAB-CTA-SCH.
-
The datasets zip file includes:
- The training set is found in the file "sotab_cta_train_round2.csv" and provides the table names, column indices, and ground truth labels for each column.
- The validation set is found in the file
"sotab_cta_validation_round2.csv" and has the same structure as the
training set. You can use the code "SOTAB_Evaluator.py" to evaluate the
predictions on the validation set. You can run the evaluation by
running:
python SOTAB_Evaluator.py /path/to/submission/file /path/to/ground/truth/file - The test targets can be found in the file "sotab_cta_test_targets_round2.csv". The first column indicates the table name and the second the target column index which needs to be predicted. Submissions need to have one prediction for each target column.
- All tables can be found in the links provided. One table is stored in
one JSON file. Each line corresponds to a table row. The tables do not
have any column headers. You can open a table using the following code:
table_df = pd.read_json(path, compression='gzip', lines=True) - The label set to use for prediction is stored in the "cta_labels_round2.txt" file.
Evaluation Criteria
Calculating Precision, Recall, Macro-F1 Score and Micro-F1 Score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_DATASET_TASK.csv.Columns Property Annotation using Schema.org terms (R2-SOTAB-CPA-SCH)
R2-SOTAB-CPA-SCH is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". It is based on the WDC-SOTAB benchmark. The goal is to annotate the relationship between the main column of a table and other columns with some pre-defined terms from the Schema.org vocabulary.
Task Description
In this task, the goal is to annotate the relationship between the main column of a table and other columns using terms from a pre-defined set of Schema.org terms. The problem is formulated as a multi-class classification problem where each column pair can be annotated with only one label. The set of pre-defined Schema.org terms consists of 105 terms which are listed in the "cpa_labels_round2.txt" file. Examples include telephone, isbn or description.
Each submission should be a CSV file. A line should represent one relationship prediction. The first column should specify the name of the table, the second column should specify the index of the main column, the third should specify the index of the other column and the fourth column should specify the predicted label. The columns should be named: "table_name", "main_column_index", "column_index", "label".
Explanations:
- "table_name" column should include the full name of the table including the extension. (example: Product_corememoriesco.com_September2020_CPA.json.gz)
- "main_column_index" refers to the position of the main column in the table. Main column indices in the WDC-SOTAB benchmark are always at the 0 index.
- "column_index" refers to the position of the column in the table. Non-main-column indices in a table start from 1.
- "label" refers to the predicted label. One column pair should have only one predicted label.
Dataset
- Links
- (1) R2-SOTAB-CPA Tables at SemTab 2023 Round 2
- Description
- (2) Training annotations, validation annotations, test targets, evaluation script and label space for R2-SOTAB-CPA-SCH.
-
The datasets zip file includes:
- The training set is found in the file "sotab_cpa_train_round2.csv" and provides the table names, main column indices, column indices, and ground truth labels for each column pair.
- The validation set is found in the file
"sotab_cpa_validation_round2.csv" and has the same structure as the
training set. You can use the code "SOTAB_Evaluator.py" to evaluate the
predictions on the validation set. You can run the evaluation by
running:
python SOTAB_Evaluator.py /path/to/submission/file /path/to/ground/truth/file - The test targets can be found in the file "sotab_cpa_test_targets_round2.csv". The first column indicates the table name, the second column indicates the index of the main column in the table, the third column indicates the target column index and the relationship between these two columns needs to be predicted. Submissions need to have one prediction for each target column.
- All tables can be found in the links provided. One table is stored in
one JSON file. Each line corresponds to a table row. The tables do not
have any column headers. You can open a table using the following code:
table_df = pd.read_json(path, compression='gzip', lines=True) - The label set to use for prediction is stored in the "cpa_labels_round2.txt" file.
Evaluation Criteria
Calculating Precision, Recall, Macro-F1 Score and Micro-F1 Score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_DATASET_TASK.csv.Column Type Annotation using DBpedia (R2-SOTAB-CTA-DBP)
R2-SOTAB-CTA-DBP is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". It is based on the WDC-SOTAB benchmark. The goal is to annotate table columns with pre-defined terms from DBpedia.
Task Description
In this task, the goal is to annotate the semantic types of table columns using terms from a pre-defined set of DBpedia terms. The problem is formulated as a multi-class classification problem where each column can be annotated with only one type. The set of pre-defined Schema.org terms consists of 46 terms which are listed in the "cta_labels_round2_dbpedia.txt" file.
Each submission should be a CSV file. A line should represent one column prediction. The first column should specify the name of the table, the second column should specify the index of the column in the table and the third column should specify the predicted label. The columns should be named: "table_name", "column_index", "label".
Explanations:
- "table_name" column should include the full name of the table including the extension. (example: Product_corememoriesco.com_September2020_CTA.json.gz)
- "column_index" refers to the position of the column in the table. Column indices in a table start from 0.
- "label" refers to the predicted label. One column should have only one predicted label.
Dataset
- Links
- (1) R2-SOTAB-CTA Tables at SemTab 2023 Round 2
- Description
- (2) Training annotations, validation annotations, test targets, evaluation script and label space for R2-SOTAB-CTA-DBP.
-
The datasets zip file includes:
- The training set is found in the file "sotab_cta_train_round2_dbpedia.csv" and provides the table names, column indices, and ground truth labels for each column.
- The validation set is found in the file
"sotab_cta_validation_round2_dbpedia.csv" and has the same structure as the
training set. You can use the code "SOTAB_Evaluator.py" to evaluate the
predictions on the validation set. You can run the evaluation by
running:
python SOTAB_Evaluator.py /path/to/submission/file /path/to/ground/truth/file - The test targets can be found in the file "sotab_cta_test_targets_round2_dbpedia.csv". The first column indicates the table name and the second the target column index which needs to be predicted. Submissions need to have one prediction for each target column.
- All tables can be found in the links provided. One table is stored in
one JSON file. Each line corresponds to a table row. The tables do not
have any column headers. You can open a table using the following code:
table_df = pd.read_json(path, compression='gzip', lines=True) - The label set to use for prediction is stored in the "cta_labels_round2_dbpedia.txt" file.
Evaluation Criteria
Calculating Precision, Recall, Macro-F1 Score and Micro-F1 Score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_DATASET_TASK.csv.Columns Property Annotation using DBpedia (R2-SOTAB-CPA-DBP)
R2-SOTAB-CPA-DBP is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". It is based on the WDC-SOTAB benchmark. The goal is to annotate the relationship between the main column of a table and other columns with some pre-defined terms from DBpedia.
Task Description
In this task, the goal is to annotate the relationship between the main column of a table and other columns using terms from a pre-defined set of DBpedia terms. The problem is formulated as a multi-class classification problem where each column pair can be annotated with only one label. The set of pre-defined DBpedia terms consists of 49 terms which are listed in the "cpa_labels_round2_dbpedia.txt" file.
Each submission should be a CSV file. A line should represent one relationship prediction. The first column should specify the name of the table, the second column should specify the index of the main column, the third should specify the index of the other column and the fourth column should specify the predicted label. The columns should be named: "table_name", "main_column_index", "column_index", "label".
Explanations:
- "table_name" column should include the full name of the table including the extension. (example: Product_corememoriesco.com_September2020_CPA.json.gz)
- "main_column_index" refers to the position of the main column in the table. Main column indices in the WDC-SOTAB benchmark are always at the 0 index.
- "column_index" refers to the position of the column in the table. Non-main-column indices in a table start from 1.
- "label" refers to the predicted label. One column pair should have only one predicted label.
Dataset
- Links
- (1) R2-SOTAB-CPA Tables at SemTab 2023 Round 2
- Description
- (2) Training annotations, validation annotations, test targets, evaluation script and label space for R2-SOTAB-CPA-DBP.
-
The datasets zip file includes:
- The training set is found in the file "sotab_cpa_train_round2_dbpedia.csv" and provides the table names, main column indices, column indices, and ground truth labels for each column pair.
- The validation set is found in the file
"sotab_cpa_validation_round2_dbpedia.csv" and has the same structure as the
training set. You can use the code "SOTAB_Evaluator.py" to evaluate the
predictions on the validation set. You can run the evaluation by
running:
python SOTAB_Evaluator.py /path/to/submission/file /path/to/ground/truth/file - The test targets can be found in the file "sotab_cpa_test_targets_round2_dbpedia.csv". The first column indicates the table name, the second column indicates the index of the main column in the table, the third column indicates the target column index and the relationship between these two columns needs to be predicted. Submissions need to have one prediction for each target column.
- All tables can be found in the links provided. One table is stored in
one JSON file. Each line corresponds to a table row. The tables do not
have any column headers. You can open a table using the following code:
table_df = pd.read_json(path, compression='gzip', lines=True) - The label set to use for prediction is stored in the "cpa_labels_round2_dbpedia.txt" file.
Evaluation Criteria
Calculating Precision, Recall, Macro-F1 Score and Micro-F1 Score.
Submission
Participants can test and develop their systems on the given ground truth (validation set). Please name your submission files as YOURTEAM_DATASET_TASK.csv.Column-Qualifier Annotation (R2-QA)
R2-CQA is a task of ISWC 2023 "Semantic Web Challenge on Tabular Data to Knowledge Graph Matching". The goal of this task is to predict both main properties and qualifiers from Wikidata for n-ary relations that are expressed by three table columns. This dataset is further explaned here: https://github.com/bennokr/semtab2023-CQA/ .
Task description
The goal of this task is to predict both main properties and qualifiers from Wikidata for n-ary relations that are expressed by three table columns. For example, given the following table about Oscar nominations:
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Academy Award for Best Actor | 2000(73rd) | Russell Crowe | Gladiator | Maximus Decimus Meridius |
| Academy Award for Best Actor | 2000(73rd) | Javier Bardem | Before Night Falls | Reinaldo Arenas |
| Academy Award for Best Actor | 2000(73rd) | Ed Harris | Pollock | Jackson Pollock |
the main property "nominated for" (P1411) holds between columns 2 and 0 (the subject and object column), which is expanded upon with the qualifier "for work" (1686) in column 3 (the qualifier column). This property-qualifier pair describes the n-ary relation that holds between these three columns.
In this repository you will find an example evaluation dataset
(simple) with a baseline, and a full dataset for the SemTab2023 challenge (full-semtab2023-CQA.zip)
which includes training data. In both datasets, the file task.csv specifies
which columns in each table should be annotated with properties and qualifiers. Submissions
must fill in the empty cells, and will be evaluated on their accuracy of predicting the
correct property-qualifier pair (see evaluate.py).
wikidata_main_property_labels.csv and
wikidata_qualifier_labels.csv.
Each submission should be a CSV file formatted in the same way as the
solution.csv file of the simple dataset.
Dataset
- Dataset repository
- https://github.com/bennokr/semtab2023-CQA/ (includes baseline code notebook)
- Link
- Full dataset for R2-CQA (includes training data).
Evaluation Criteria
Submissions will be evaluated on their accuracy of predicting the correct property-qualifier pair (see evaluate.py).
Submission
Please name your submission files as YOURTEAM_CQA.csv.Accuracy Track Results
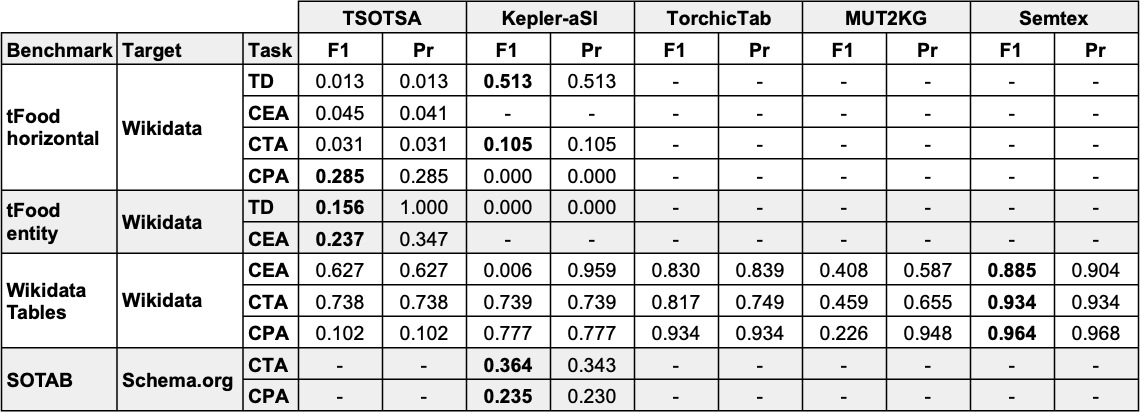
Round 1 Results Summary
Round 2 Results Summary

Paper Guidelines
We invite participants in the Accuracy Track as well as the Datasets Track to submit a
paper, using easychair.
System papers in the Accuracy Track should be no more than 12 pages
long (excluding references) and papers for the Datasets Track are
limited to 6 pages.
If you are submitting to the Datasets Track, please append "[Datasets Track]" at the end
of the
paper title.
Both type of papers should be formatted using the
CEUR Latex template
or the
CEUR Word template. Papers will be reviewed by 1-2 challenge
organisers.
Accepted papers will be published as a volume of CEUR-WS. By submitting a paper, the authors accept the CEUR-WS publishing rules.
Organisation
This challenge is organised by Kavitha Srinivas (IBM Research), Ernesto Jiménez-Ruiz (City, University of London; University of Oslo), Oktie Hassanzadeh (IBM Research), Jiaoyan Chen (University of Oxford), Vasilis Efthymiou (FORTH - ICS), Vincenzo Cutrona (SUPSI), Juan Sequeda (data.world), Nora Abdelmageed (University of Jena), and Madelon Hulsebos (Sigma Computing, University of Amsterdam). If you have any problems working with the datasets or any suggestions related to this challenge, do not hesitate to contact us via the discussion group.
Acknowledgements
The challenge is currently supported by the SIRIUS Centre for Research-driven Innovation and IBM Research.






