Description
The evaluation of systems regarding accuracy is similar to prior versions of the SemTab. That is, to illustrate the accuracy of the submissions, we evaluate systems on typical multi-class classification metrics as detailed below. In addition, we adopt the "cscore" for the CTA task to reflect the distance in the type hierarchy between the predicted column type and the ground truth semantic type.
Matching Tasks:
- CTA Task: Assigning a semantic type (a Wikidata class as fine-grained as possible) to a column
- CEA Task: Matching a cell to a Wikidata entity
- CPA Task: Assigning a Wikidata property to the relationship between two columns
- RA Task: Assigning a Wikidata entity to a table row
- TD Task: Assigning a Wikidata class to a table
Table Types:
- Horizontal Tables: A grid where each row represents one entity and each column shares the same semantic type.
- Entity Tables: A list of rows describe an entity/ a thing, where each row represents a property for that entity.
Horizontal Table Example:
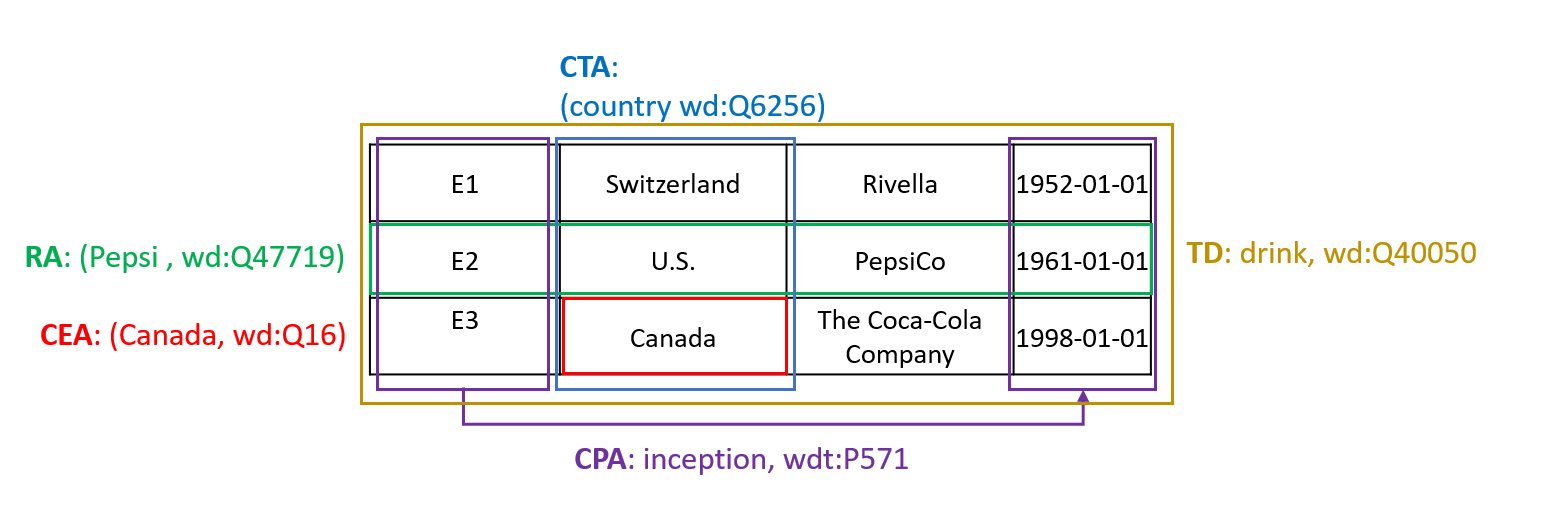
Entity Table Example:

Evaluation Criteria
Precision, Recall and F1 Score are calculated: \[Precision = {{correct\_annotations \#} \over {submitted\_annotations \#}}\] \[Recall = {{correct\_annotations \#} \over {ground\_truth\_annotations \#}}\] \[F1 = {2 \times Precision \times Recall \over Precision + Recall}\]
Notes:
- # denotes the number.
- \(F1\) is used as the primary score, and \(Precision\) is used as the secondary score.
- One target cell, one ground truth annotation, i.e., # ground truth annotations = # target cells. The ground truth annotation has already covered all equivalent entities (e.g., wiki page redirected entities); the ground truth is hit if one of its equivalent entities is hit.
Round 1
Datasets
- WikidataTables2024R1:
 Get WikidataTables2024R1.tar.gz from zenodo. This is the
2024 Round 1 version of our classic WikidataTables dataset, consisting of
30K tables.
Get WikidataTables2024R1.tar.gz from zenodo. This is the
2024 Round 1 version of our classic WikidataTables dataset, consisting of
30K tables.
- tBiodiv:

- tBiomed:

Round 2
Datasets
Round 2 datasets are larger versions of Round 1 datasets. The main goal here is to measure the accuracy of more scalable solutions, as there is often a tradeoff between accuracy and performance.
- WikidataTables2024R2:
Get WikidataTables2024R2.tar.gz from zenodo.
This dataset is very similar to Round 1 dataset, with slightly different characteristics, and 78,745
tables.
- tBiodivL - Large:

- tBiomedL - Large:

Target Knowledge Graph: Wikidata. For offline, use March 20, 2024 dump. Reach out to the organizers if you need assistance in setting up a triplestore.
Datasets' Structure
All datasets consist of two data folds (training and validation). WikidataTables are all relational (horizontal) tables. tBiodiv and tBiomed have two table types entity (vertical) and relational (horizontal) tables with the following supported tasks:
Supported Task
- WikidataTables: CEA, CTA, CPA
- Relational tables of tBiomed & tBiodiv: CEA, CTA, CPA, RA, TD
- Entity tables of tBiomed & tBiodiv: CEA, RA, TD
Targets Format
- CEA: table name, column id, row id
- CTA: table name, column id
- CPA: table name, subject column id, object column id
- RA: table name, row id
- TD: table name
- Notes:
- - table name is filename without the extention.
- - column, row ids are zero based.
- - targets indicates what to solve in each task.
- - ground truth (gt) indicates the solution of each target.
- - ground truth (gt) format is the same as targets with the QID of corresponding Wikidata entity/class/property.
Participate!
Submission: Are you ready? Then, submit the results of the test set using the following forms: